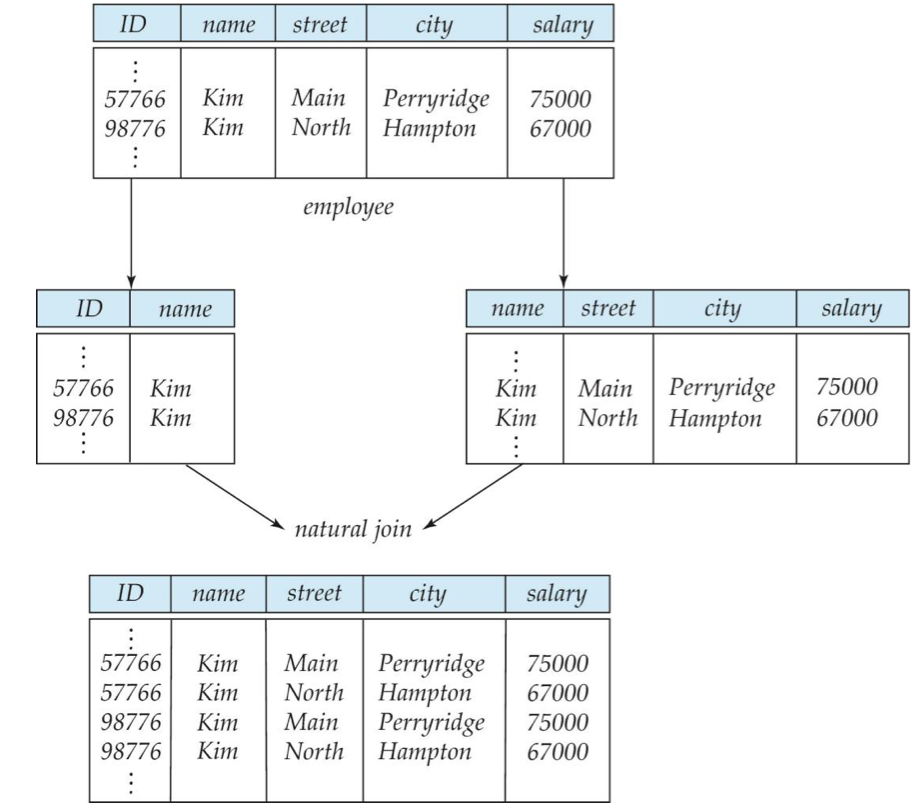
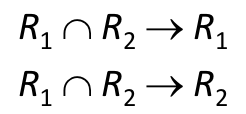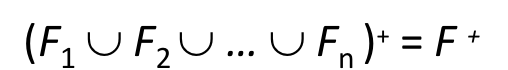A->H >> A->B 이고 B->H 이므로 transitive 속성으로 A->H 인 것을 추가적으로 알 수 있다.
AG->I >> A->C 이므로 augmentation 속성으로 AG->CG 이고 따라서 CG->I 이므로 transitivity속성으로 AG->I인 것도 알 수 있다.
CG->HI >> CG->I 의 augmentation 속성으로 CG->CGI 인것을 알 수 있고 CG->H 는 augmentation 속성으로 CGI->HI 인 것도 알 수 있다. 따라서 CG->CGI , CGI->HI 이므로 transitivity 속성을 이용해 CG->Hi 인것까지 구해낼 수 있다.
F+를 구하는 알고리즘을 간략하게 말하면 우선 reflexivity 와 augmentation의 속성들을 다 찾아서 더한 후에
transitivity의 속성을 원래 F와 추가된 속성에서 찾아내서 더이상의 f+에 덜할 것이 없을때까지 반복문을 돌리는 것이다.
attribute가 n개 라면 2^2n의 개수가 나올수 있어 알고리즘 수행시간은 O(2^n)이다.
이때까지 했던 것은 "Closure of Functional Dependency" 였다. 이제 "Closure of Attribute Sets"에 대해서 알아보자.
attribute set이 a 라고 한다면 a로 부터 도달할 수 있는 모든 것들을 a+라고 한다.
예) R = { A,B,C} // F = {A->B, B->C}라고 한다면 A+는 {A,B,C} 인 것이다.
이때 a+가 R가 똑같다면 a 는 그 relation의 key 라고 한다!
이것에 대한 알고리즘은 간략하게 말하자면 a 로 부터 도달 가능한 것들을 result라고 하고 a를 먼저 result 에 넣어준다. 반복문을 돌 때 b가 현재 result에 있고 b->r의 관계를 발견한다면 result에 r도 추가시키는 것이다. 이것의 수행시간은 n+n-1+,,+1 = O(n^2) 이다.
ex) R = ( A,B,C,G,H,I ), F = { A->B, A->C, CG->H, CG->I, B->H }
(AG)+ 는
1. result = AG
2. result = ABCG ( A->C and A->B )
3. result = ABCGH ( CG->H and CG는 AGBC 에 속한다. )
4. result = ABCGHI ( CG->I and CG는 AGBCH 에 속한다.)
AG는 candidate key 인가 >> super key 는 맞으나 A와 G 각각이 key 가 아니라면 candidate key 의 조건 까지 만족한다.
Attribute Closure 를 사용하는 것은 슈퍼 키인지 판단하거나 Functional dependencies를 만족하는지 판단 할 때 사용한다.
Lossless-join Decomposition
Lossless-join을 만족시키려면 위의 사진처럼 둘 중 하나의 조건은 만족해야한다.
만약 r( A, B, C, D) 라면 (A,B)//(C,D) 이렇게 는 분해 할 수 없다.
(A,B)//(A,C,D) -->> 이렇게 decomposition을 하고 A 가 R1 가 R2에서 key의 역할을 하고 있어야한다ㅏ.
첫 번째 분해 시에 (A,B) 와 (B,C) 로 하면 R1과 R2의 교집합인 B이고 B는 R2에 속하기 때문에 Lossless를 보장하고 있다.
추가적으로 FD를 각각의 relation을 join 하지 않고 각각으로 검사가 가능하기 때문에 Dependency preserving 또한 보장된다.
하지만 B->R 이 아닌 상태에서 키의 역할을 하고 있기 때문에 BCNF는 아니다.
두 번째 분해는 (A,B) (A,C)로 하면 두 테이블의 교집합인 A가 R1에 속하기 때문에 lossless는 보장한다.
추가적으로 각각의 릴레이션을 조인하지 않고 FD를 검사하는 것은 불가능하기 때문에 Dependency preserving은 보장하지 않는다.
마지막으로 두 relation의 key인 A가 A->R이기 때문에 BCNF는 만족한다.
Dependency Preservation
Ri 의 FD 를 Fi 라고 할 때, DP가 보장된다는 것은
위 사진의 조건을 만족한다는 것이다. 즉 각각의 릴레이션에 대한 functional dependency를 모으면 F+가 만들어진다는 것.
만약 DP가 보장이 안된다면 = 이 아닌 ⊆ 의 형태일 것이다.
위의 사진을 설명하자면 JK->L 이므로 JK->JKL 따라서 JK->R 이다. 즉 JK 는 이 릴레이션의 KEY이다.
또한 L->K, JL->JK, JL->JKL의 과정을 거쳐서 JL->R인 것을 확인할 수 있어 JL도 이 릴레이션의 KEY이다.
KEY = [J,K] 로 L->K의 조건때문에 L 은 KEY가 아닌데 왼쪽에 위치하여 이 릴레이션은 BCNF가 아닌 것을 알 수 있다.
Decomposition을 해야하므로 L->K의 조건으로 a->b 일때 a교집합b 와 R-(b-a)로 분해하면
R1=(J,L) R2=(L,K)로 분해된다. 이때 key 들이 fd의 왼쪽에 위치하고 있기에 BCNF 이지만 조인을 하지 않고서는 FD를 검사할 수 없기 때문에 DP를 만족한다고 볼 수 없다.
따라서 분해 전의 상황을 보면 r(J,K,L) 일때 JK->L L->K 일때 JK->K transitivity 속성을 이용한 것이 아니기때문에 3NF는 만족한다고 볼 수 있다.
📌BCNF : lossless 만족, key들은 FD의 왼쪽에 있어야함, DP는 보장되지 못할 수도 있다
Deadlock 은 한 프로세스가 특정 resoucre를 소유한 상태에서 다른 프로세스가 소유한 resource를 요청 시에 발생할 수 있다.
위에 적었듯이 프로세스가 하나일 땐 데드락이 발생하지 않습니다. 포괄적으로 말하면 프로세스와 리소스 사이의 관계에 의해 발생 가능하고, 특히 프로세스는 한 개가 아니라 여러 개일 때 일어납니다.
📌 Bridge crossing example
데드락을 설명 시에 가장 대표적인 예시입니다. 자동차를 프로세스, 도로를 리소스라고 가정해봅시다.
왼쪽(->)에서 오고있는 자동차는 1차선의 왼쪽을 차지하고 있는 상태이고,
오른쪽(<-)에서 오고있는 자동차는 1차선의 오른쪽을 차지하고 있는 상태입니다.
이때 서로의 도로(리소스)를 요청하고 있는 상황이고, 이는 두 차 모두 진행될 수 없기 때문에 데드락 상황입니다.
Solve this problem
Kill the process - 데드락을 없애기위해 프로세스를 삭제하는 방법
Back the car up ( 후진 ) - preempt the resource and rollback. : 이전 상태중 특정상태로 돌아가는 방법 ( 데드락을 피하기 위해)
+ checkpoint : 라인 바이 라인으로 코드를 수행하는데 특정상태로 돌아가는 것은 매우 힘듭니다. 그래서 특정 상황에서 그때의 상태가 담긴 "context"를 저장해야하고 그 저장하는 공간을 checkpoint 라고 합니다. 따라서, 2번의 방법을 사용하기 위해선 주기적으로 checkpoint를 둬서 context를 저장해야만합니다. 저장을 해놓았다면 그 특정 부분으로 돌아가는 것이 가능합니다.
이제 앞으로 배울 간단한 목차에 대해서 설명하면
Deadlock detection : 데드락을 어떻게 검출할 것인지
Deadlock avoidance : 데드락이 예상된다면 데드락을 만나기 전에 회피하는 것
Deadlock recovery : 데드락이 발생했다면 어떻게 없앨것인지.
Deadlock prevention : 데드락을 어떻게 예방할 것인지
등을 배울 예정입니다.
그전에
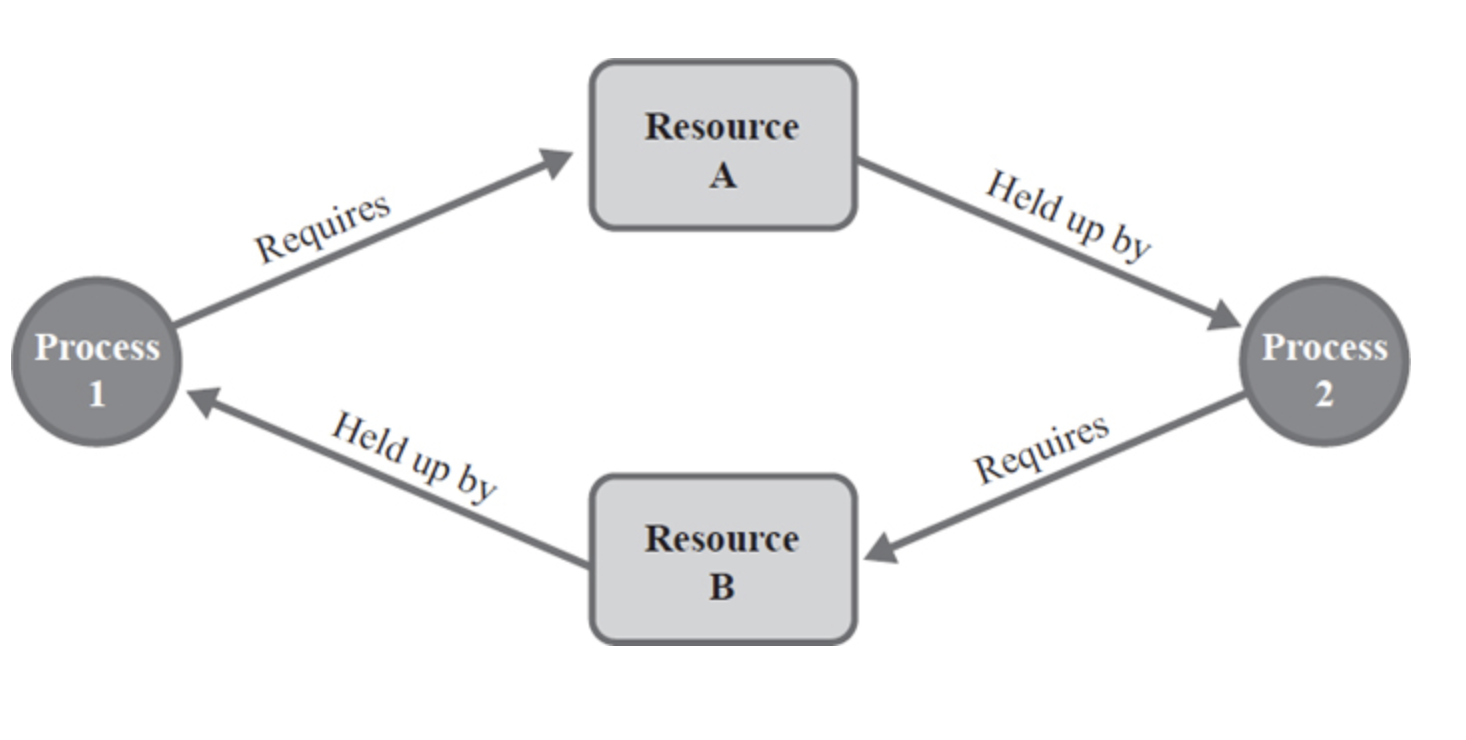
📌 Resource Allocation Graph = (RAG) = 자원할당 그래프
: deadlock이 발생했는지 알아보기 위해 사용.
리소스가 프로세스에게 어떻게 할당되는지 그래프 형태로 그림을 그린 것.
사용이유? deadlock을 쉽게 detect 할 수 있음.
- 동그라미는 Process, 네모는 Resource. 네모 안의 네모는 자원의 수를 나타내는 instance
- Assignment edge : 자원 -> 프로세스 (이 프로세스가 해당 자원을 가지고 있다.)
- Request edge : 프로세스 -> 자원 (이 프로세스가 해당 자원을 요청. 아직 획득하진 못함)
>> Deadlock의 필요조건 : "Hold & Wait " : 자원을 하나 가지고 있고 다른 프로세스가 소유한 다른 자원을 달라고 요청하는 상황
📌Deadlock Necessary Condition
Mutual exclusion : 오직 하나의 프로세스만 특정 리소스 소유 가능
mutual exclusion 을 보장 안한다면 wait 할 상황이 없다..! 그냥 여러 프로세스가 자원 공유해서 쓰면 됨.
Hold and wait : 한 리소스를 hold한 상태에서 이미 다른 프로세스가 소유한 리소스를 요청하면 wait >> hold&wait
No preemption : 먼저 실행된 프로세스가 자발적으로 리소스를 놓아야 다른 프로세스가 사용가능
preemption 이 된다면 critical section 에 프로세스 여러 개 들어가는 상황. 1번과 유사하게 데드락 발생 가능성 제로
Circular wait : Hold & wait 의 좁은 개념. 리소스를 wait 하는 상황이 싸이클을 이루는 것
>> 이 조건이 다 만족했다고 데드락이라는 것이 아닌 데드락이 발생하면 이 조건들은 모두 만족해야한다.!!
따라서 1.3번은 당연하고 2번은 4번의 큰 개념이므로 4번이 있는지만 체크하면 데드락의 가능성을 체크할 수 있는 것!!
4번이 성립하지 않으면 데드락은 없다..! but 4번이 있다고해서 무조건 데드락인건 아니궁!!
위에서 설명한 " 사이클이 있어도 데드락이 발생하지 않는 경우" 에 대해서 설명드리겠습니다.
데드락의 키워드는 어떠한 경우에도 "indefinetly blocking" 입니다. 어떤 해결책이 없이 계속 데드락이 걸리는 상황이어야하는 것입니다.
위의 그림은 사이클이 있다고 하더라도 리소스를 가지고 있던 프로세스가 리소스를 release하면 원래는 request edge가 assignment edge 로 바뀌면서 사이클이 사라질 수 있습니다. 즉 상황이 지나면 사이클이 사라지기 때문에 사이클이 있다고 해서 무조건 데드락이 있는 것은 아닙니다.
조금 더 자세하게 알아보면, 위의 그림은 리소스의 instance가 여러 개라서 데드락이 발생하지 않았습니다.
즉, 리소스의 인스턴스 개수에 따라 데드락 발생확률이 다릅니다.
>> 만약 1개의 인스턴스를 가지고 있고 싸이클이 있다면 데드락의 필요충분조건입니다.
>> 만약 여러 개의 인스턴스를 가지고 있고, 싸이클이 있다면, 필요조건입니다.
📌 Methods for Handling Deadlocks
- Deadlock Avoidance : 프로그램을 수행하면 데드락이 발생할 것이 미리 보이면 safe state( 절대 데드락이 발생하지 않을 상태 )까지 프로그램 수행을 멈춤
- Deadlock Prevention : 데드락의 필요조건(4가지)을 없애는 것
- Deadlock Detection, Recover : 데드락이 발생했다면, 데드락이 발생한 것을 탐지(Detection)하고 데드락을 없애기위해 회복절차를 거치는것(recover : kill or rollback)
위에서 설명햇던 네가지를 좀더 자세하게 알아보자.
Deadlock Prevention
: 데드락 발생가능 이유를 제거합니다. 즉 위에서 설명한 필요조건을 한 개를 제거합니다.
조건을 없애는게 불가능하면 infeasibility 하다고 하고, 조건을 없앨 수는 있으나 부작용이 생기는 것을 side effect가 발생할 수 있는 조건이라고 명시하겠습니다. 그러면 데드락의 필요조건 네 가지에 대해 살펴봅시다.
Mutual exclusion
mutual exclusion을 없애면 race condition이 발생할 수도 있습니다. 즉 불가능한 조건이므로 " infeasibility " 입니다.
Hold and wait
자원을 다른 프로세스가 소유하지 않았을때만 요청을 할 수 있게 하면 됩니다. 그렇게 된다면 request edge 가 바로 assignment edge가 됩니다.
위의 방식으로 진행하게 되면 낮은 자원 이용률을 야기시키는 " side effect " 가 발생합니다.
예 ) p1 이 r1,r2를 요청하고 싶어합니다. 이때 p2 가 r2를 사용중이라면 p1 은 r1 에게도 r2에게도 요청신호를 보낼 수 없게 되어 자원 이용률이 떨어지는 것입니다. 동시에 p1은 그 어떤 자원도 쓰고 있지 않기때문에 "starvation" 현상도 일어날 수 있습니다.
No preemption
cpu에서는 preemption 이 가능하나, 프린터는 preemption이 된다면 출력 결과물이 이상하게 출력될 것이다. 즉 infeasible 하다고 볼 수 있다.
Circular wait : Hold & wait 의 좁은 개념. 리소스를 wait 하는 상황이 싸이클을 이루는 것
모든 리소스에 우선순위를 매겨서 순서대로만 요청할 수 있도록 한다. 이와같이 리소스 타입에 ordering을 보장하면 circular wait 이 발생할 일이 없다.
예 ) r1 - r2 즉 r1을 먼저 요청해야한다고 가정하자. p1 이 r1을 소유하고 그 다음에 r2를 소유 요청을 할 수 있다. 이때 p1이 r1을 소유한 상태에서 p2는 r1 요청을 보내도 기다려야하고 r1을 먼저 요청한 후 r2를 요청해야하기때문에 r2로는 아예 요청 신호조차 보낼 수 없다.
2번과 마찬가지로 리소스를 활용할 확률이 떨어지기 때문에 side effect로 resource utilization 이 떨어진다고 볼 수 잇다
Deadlock Avoidance
가정 : 리소스 타입별 리소스 요구량의 최대의 개수가 몇 개인지 알고 있어야한다. 왜냐하면 요청 개수 보다 이용가능한 리소스의 개수가 많다면 그때는 절대 데드락이 일어나지 않는 safe state에 머물기때문에 deadlock avoidance를 할 이유가 없어지기 때문이다.
따라서 우리는 resource-allocation state 를 알고 있어야한다. 여기에는 이용가능한 자원의수, 할당된 자원의 수, 최대 요청 개수에 관련된 정보가 있다.
목표 : 프로세스가 안전하지 못한 상태로 진입하지 않도록 보장하는 것. >> 안전하지 못한 상태이면 데드락의 가능성이 생기기 때문
unsafe state : # of requests <= # of available resources.
기본 로직 : 프로세스 수행 시퀀스를 정해 안전한 상태를 만족하도록 하는 것.
다실 말하자면, 프로세스의 수행 순서를 정하는 것이 핵심이다. 안전한 순서라고 함은 할당된 자원과 추가적으로 요구된 자원이 가용한 자원보다 적거나 같으면 된다. 이때 먼저 수행하고 있던 프로세스가 종료되면 리소스를 반환한다. 종료되는 프로세스가 증가할수록 이용가능한 자원은 증가하게되고 그럴수록 안전한 상태를 유지하는 확률이 높아진다.
Maximum needs
Current needs
# of request
P0
10
5
5
P1
4
2
2
P2
9
2
7
이용가능한 자원의 개수가 12개라고 해보자 현재 사용중인 자원의 수는 5+2+2 = 9 개 이므로 이용가능한 자원의 수는 => 3개이다.
이용가능한 자원의 수보다 요청 개수가 작아야하므로 P1을 먼저 수행해야 하는 것이다.
이렇게 되면 현재 이용하고 있는 자원의 수는 11개로 12개보다 작기 때문에 데드락에 걸리지않는다. 이때 P0,P2는 stop 상태여야한다.
언제까지 ?? p1이 종료될때까지!!
이후 p1의 종료되고 쓰던 자원들을 다 반환 하면 이용중인 자원의수는 5+2 = 7개 로 5개의 자원이 추가로 이용가능하기에 p0 에게 먼저 할당. p2는 stop >> p0 terminate >> p2 에게 할당.
즉 프로세스가 종료되면서 자원들을 반환하기때문에 안전한 순서라고 함은 요청 개수가 작은 프로세스를 먼저 수행하고 나머지 프로세스들은 대기하고 있는 것이다. 이후 자원을 할당받은 프로세스가 종료되고 자원을 반환하면 대기하고 있던 프로세스 중 요청개수가 적은 프로세스에게 할당하는 순서로 진행된다.
이처럼 자원의 개수가 데드락을 결정하는데 중요한 요소이다. 이때 자원의 개수에 따라 조금은 다르게 적용해야한다.
1. single instance of resource type : 모든 리소스 타입이 한개라면 사이클이 있다면 바로 데드락이기 때문에 데드락 탐지가 매우 용이하게 적용된다. RAG 만 이용하면된다.
2. multiple instance of resource type : 인스턴스 개수가 여러개라면 사이클이 발생해도 데드락이 발생하지 않을 수 있어서
Banker's Algorithm을 사용할 것이다.
+ Banker's Algorithm : 위에서 설명했던 안전한 상태를 만족시키는 순서를 만드는게 핵심입니다. 즉, 리소스를 적게 요구하는 프로세스를 먼저 실행하는 것. 시간이 지날수록 리소스 수가 많아지니까.
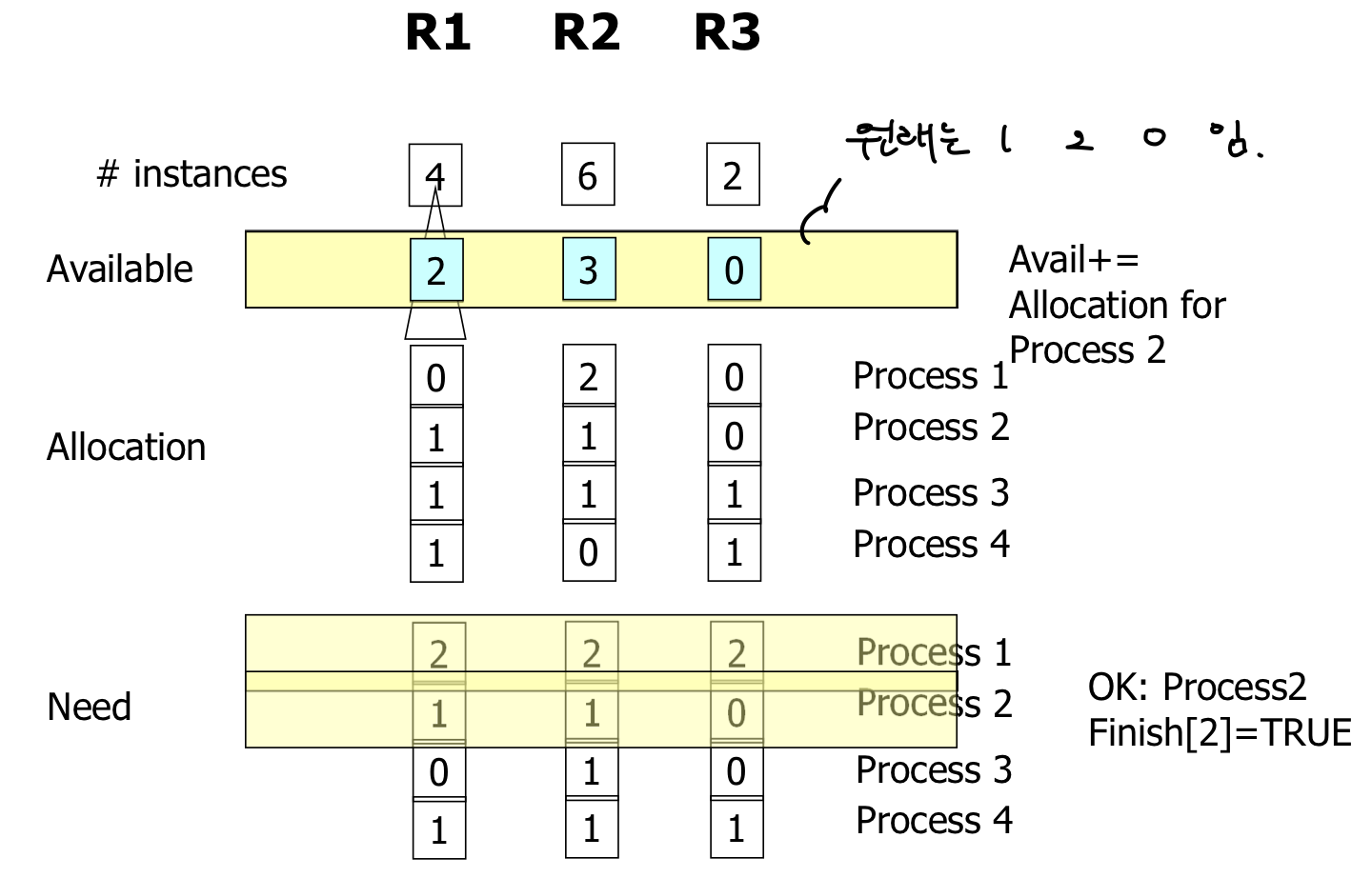
이용가능한 자원의 수가 1/2/0 인데 이 숫자보다 작게 요청개수를 가진 프로세스는 프로세스 2 이다 (1/1/0) 이므로.
따라서 프로세스2에게 먼저 할당한다. 이후에 프로세스가 종료되고 자원을 반환하면 2/3/0 이 된다.
( 이용가능한 자원의 숫자에 need 자원의 수는 더할 필요 없다. 어차피 available - need + need 이기 때문에..)
가능한 프로세스 넘버가 작은 순서대로 먼저 실행하지만 요청개수가 이용가능한 자원의 수보다 많다면 그 다음 프로세스로 넘어가는것.
따라서 프로세스 2 -> 프로세스 3 -> 프로세스 4 -> 프로세스 1 순서로 수행될 것이다.
Deadlock Detection
single instance 에서는 사이클 생기면 데드락 발생
multiple instance 에서
avoidance 에서의 need는 미래의 리소스 요청 개수였다면 need = MAX - allocation
여기서는 need는 현재 실제 요청값을 나타낸다. 왜냐하면 detection은 현재 데드락이 발생했는지 보는 것이기 때문.
need = real requests6
Deadlock Recovelry
1. kill the process - 사이클이 없어질때까지
어떤 프로세스를 종료시킬지?
관련 모든 프로세스를 종료
step by step 으로 사이클이 안보일대까지 종료 ( 우선순위 or. 얼마나 많은 리소스를 추가적으로 요구할건지)
이전에 배웠었던 instructor 와 department 스키마를 combine한 schema가 있다고 가정해보자.
우리는 이전에 배웠던 스키마가 더 좋은 스키마라고 알고있다. 그러면 지금 이 big_instructor 스키마를 어떨때 decomposition 하는 것이 맞는지 그리고 어떻게 decompositon 하는 것이 맞는지에 대해 알아보려고한다.
그전에 잠시 functional dependency에 이야기해보자.
💡Functional Dependency
관계형 데이터베이스의 설계에서 중복된 데이터가 최소화되도록 데이터베이스의 구조를 결정하는 것을 정규화 (normalization)라고 한다. 정규화된 데이터베이스가 그렇지 않은 데이터베이스에 비하여 더욱 효율적으로 데이터에 대한 연산을 수행할 수 있는 것은 매우 당연한 것이다. 이러한 데이터베이스의 정규화 과정에서 'Functional Dependency'이라는 개념은 매우 중요하게 이용된다.
Functional Dependency은 수학에서의 함수와 같이 두 필드의 집합이 many-to-one 관계로 사상되는 것을 말한다. 즉, 함수와 같이 어떠한 값을 통해 종속 관계에 있는 다른 값을 유일하게 결정할 수 있다는 것이다. 데이터베이스에서의 함수 종속성을 더욱 명확하게 정의하면 다음과 같다.
어떤 테이블 RR에 존재하는 필드들의 부분집합을 각각XX와YY라고 할 때,XX의 한 값이YY에 속한 오직 하나의 값에만 사상될 경우에 "YY는XX에 함수 종속 (YYis functionally dependent onXX)"이라고 하며,XX→YY라고 표기한다.
예를 들어, 테이블에 [생일]과 [나이]라는 필드가 존재할 경우에 [나이] 필드는 [생일] 필드에 함수 종속이다. 즉, 생일을 알고 있다면, 나이에 대한 필드를 참조하지 않거나, 아예 필드를 유지하지 않아도 나이를 결정할 수 있다. 데이터베이스 설계 단계에서 함수 종속 관계에 있는 필드를 찾는다면, 그 만큼 중복된 데이터를 줄일 수 있다. 그러므로, 데이터베이스 설계 단계에서 각 정보들 간의 함수 종속 관계를 찾는 것은 매우 중요하다.
중복이 일어난 현상 자체를 금지하는 것이 아닌 어떤 relation이 적법한 지 정의하는 constraint를 Functional Dependencies이라고 하는 것이다. 즉 현상에 집중하는 것이 아니라 Rule에 집중한다고 보면 된다.
- Functional Dependencies require that the value for a certain set of attributes determines uniquely the value for another set of attributes. ( 어떤 attributes set은 다른 attributes set을 uniquely 하게 결정한다. )- A functional dependency is a generalization of the notion of a key. (f-d 는 일종의 key 의 개념의 일반적인 형태 == key 는 일종의 functional dependecy 이다. ) >> key에 속하는 attribute가 relation 에 있는 모든 다른 값을 결정하기 때문에 functional dependency의 일종이라고 할 수 있다.
+ Use of Functional Dependencies
: 모든 functional dependencies의 set을 "F" 라고 가정할 때, F는 두 가지로 사용될 수 있습니다.
(1) 어떤 relation 을 검사하기 위해 F 사용
(2) 사전에 relation을 정의시에 모든 F를 만족해야 생성이 가능하게 하기 위해 F 사용
Functional Dependency의 특징
Trivial : 만약 b가 a 에 속하는 속성일 때, a->b 는 trivial하게 만족한다고 볼 수 있다.
Closure : 주어진 FD 속성에서 Trivial 한 속성을 제외하고 추론을 통해 얻을 수 있는것을 closure한다고 한다.
>> 주어진 FD에서 유도할 수 있는 모든 FD를 closure 라고 하는 것.
>> closure한 속성과 trivial한 속성을 모두 합쳐놓은 집합을 F+ 라고 하고 F+ 는 F 의 superset이다.
+ F+를 구하는 과정은 O(2^n)time
Armstrong's Axioms
reflexivity: 만약 Y가 X의 부분집합이면, X→Y이다. ( Trivail 속성 )
augmentation: 만약 X→Y이면, XZ→YZ이다.
transitivity: 만약 X→Y이고 Y→Z이면, X→Z이다.
three rules are sound and complete
( 위의 규칙 세 개를 통해 나온 것은 언제나 true 이고, 3개의 규칙만 있으면 closure에 포함되어야하는 모든 FD 찾을 수 있다.)
union: 만약 X→Y이고 X→Z이면, X→YZ이다.
decomposition: 만약 X→YZ이면, X→Y이고 X→Z이다.
pseudotransitivity: X->Y 이고, YZ->A 이면 XZ -> A 이다.
잠시 functional dependency 에 대한 설명을 적었다. 다시 big_instructor의 내용으로 돌아와보자.
이 스키마에는 dept_name 이 정해지면 building 과 buget이 무엇인지 결정된다.
따라서 "Functional Dependency" 는
dept_name ---> building, budget 이라고 선언할 수 있다.
이때 dept_name 은 candidate key 가 아니기 때문에 key 가 가지고 있는 unique한 속성을 지킬 필요가 없어져서
building과 budget이 중복될 수 있음을 시사한다. 이럴때 decomposition은 필요한 것이다.
Lossy Decomposition
decomposition 시에 가장 조심해야할 부분은 원래 스키마에서 decomposition한 스키마들을 다시 조인할 시에 원래 테이블에 있던 정보와 동일해야한다. 만약 동일하지 않고 쓸데 없는 정보가 추가되는 현상을 "Lossy Decompositon" 이라고 한다.
즉 위의 사진처럼 decomposition 한 테이블을 조인한다면 name attribute 를 통해 조인을 하게되고, name은 key 의 역할을 할 수 없어서 원래 테이블과 동일한 테이블을 만들어내지 못합니다. 즉, "lossy decomposition" 이 일어났다고 보면 됩니다.
💡Lossless-join Decomposition
위에서 설명했던 lossy decomposition 과 반대되는 개념의 용어가 바로 "Lossless-join Decomposition" 이다.
다시 말해 decomposed 된 relationdmf 다시 join 했을 때 원래 relation이 나오는 것을 뜻한다.
💡1NF = First Normal Form
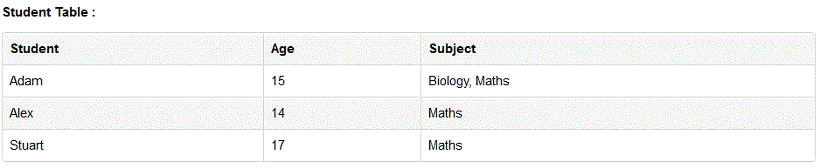
1NF는 각 로우마다 컬럼의 값이 1개씩만 있어야 합니다. 이를 컬럼이원자값(Atomic Value)를 갖는다고 합니다. 예를 들어, 아래와 같은 경우 Adam의 Subject가 Biology와 Maths 두 개 이기 때문에 1NF를 만족하지 못합니다.
즉, 추가적으로 이전에 배웠던 E-R Diagram에서 multi valued는 1NF를 만족하지 못함을 알 수 있습니다.
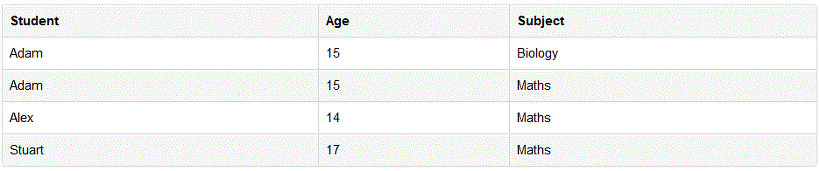
위의 정보를 표현하고 싶은 경우 이렇게 한 개의 로우를 더 만들게 됩니다. 결과적으로 1NF를 함으로써 데이터 redundancy는 더 증가하였습니다. 데이터의 논리적 구성을 위해 이 부분을 희생하는 것으로 볼 수 있습니다.
하지만 이렇게 atomic 하게 바꾸면 student age의 중복 값이 생긴 것을 확인할 수 있습니다. 즉 만약 student가 key 의 역할을 하고 있었다면 key 역할을 상실하게 되는 것을 확인할 수 있습니다.
즉 1NF는 Domain의 값이 atomic 해야하고 그
의미는 모든 테이블의 각각의 key를 가지고 있다는 의미와도 같음을 확인할 수 있습니다.
앞으로 우리가 배우는 모든 relation(=table) 들은 1NF는 무조건 만족해야한다고 가정하면서 나가겠습니다.!
추가적으로
Atomicity는 우리가 도메인의 요소들을 어떻게 사용하느냐에 달려있습니다.
예를 들어 주민번호를 주민번호 그 자체로만 사용한다면 atomicity를 만족하지만 생년월일의 정보만 사용하게된다면 divide를 해야하므로 non-atomicity 의 속성임을 확인할 수 있습니다.
따라서 주어진 정보를 application 입장에서는 그대로 이용하는 것이 좋습니다. 정보를 쪼개려고 한다면 Database 측면에서는 multivalue라고 인식하고 non atomicity이기 때문입니다.
>> Doing so is a bad idea : leads to encoding of information in application program rather than in the database.
💡BCNF ( Boyce-Codd Normal Form )
앞서 1NF : all domains are atomic == every relation should have a key 의 조건을 만족하는 것이었다.
BCNF는 1NF의 속성을 다 만족해야함과 동시에 " key를 제외한 다른 attribute는 FD를 통해 또 다른 attribute를 결정하면 안된다 " 라는 조건도 만족해야한다. 즉 FD 에. a->b 가 만족한다는 Rule 이 있다면 "a" 는 반드시 relation의 superkey 여야하는 것이다.
따라서 위에서 봤던 예제인 big_instructor에서 dept_name -> building, budget 의 rule은 big_instructor의 테이블이 BCNF를 만족하지 못하게 하는 것이다. ( dept_name이 super key 가 아니기 때문에..)
정리하면 BCNF가 되기 위해선
1. a-> b is trivial ( b는 a 에 포함)
2. a is super key for R
💡Decomposing a Schema into BCNF
스키마가 위에 언급했던 조건들을 위배한다면 조건들을 만족하여 BCNF를 만족하는 테이블을 만들기위해 decomposition을 해야합니다.
decompose 방법은 다음과 같습니다.
BCNF을 만족하지 않는 조건이 F 에서 a->b 라고 할 때
( a union b ) ( R - ( b - a ) )
위의 두 개의 테이블로 decomposition 하면 됩니다.
앞에서 계속 언급했던 예제로 한번 decomposition을 해본다면
dept_name -> building, budget 때문에 big_instructor가 BCNF 가 아니었다 따라서
a = dept_name, b = building, budget
R1 : ( a union b ) = ( dept_name, building, budget )
각각은 BCNF를 만족하고 Lossless join decomposition 인지만 확인한다면 제대로 된 분배였을 것입니다.
lossless 인지는 뒤에서 설명하도록 하겠습니다. 그전에
💡 BCNF and Dependency Preservation
어떤 attribute 관계에 대해 FD 를 사용자가 정의하고, table 을 decomposition 한 상태일 때,
각각의 relation만 가지고 (join을 하지 않은 상태 ) 모든 FD를 검사할 수 있는 상황을 " Dependency Preservation " 이라고 한다.
BCNF는 항상 Dependency Preservation을 만족하지는 않는다. 왜냐하면 조건들이 너무 까다로워서 decomposition 이 많이 일어나고, 따라서 FD를 검사하기 위해서는 테이블간의 join이 불가피한 상황이 일어날 수 있기 때문이다.
따라서 BCNF를 만족할 것이냐 Dependency Preservation을 만족할 것이냐 기로에 서있을때,
Dependency Preservation을 만족하는 것을 "3NF " 라고 한다.
💡3NF
trivial 하고 dependency preservation 을 만족하는 것
또 다른 말로
Transitivity Dependecy 가 없는 것이라고도 할 수 있다.
Transitivity Dependecy 는 a->b 이고 b->c 일때 a->b->c 의 관계가 성립하고 그때 a->c 를 알 수 있다.
즉 가운데에 있는 b를 통해 a->c 의 관계가 성립되는 것을 말한다. 만약 b 가 없이 a->c 의 관계가 성립한다면
transitivity dependency 가 성립하지 않고 3NF를 만족한다고 보면된다.
ex1
F = { ID -> dept_name, dept_name -> building, budget }
ID -> dept_name -> building, budget 으로 id -> building budget
즉, dept_name 이 없다면 관계가 성립하지 않기때문에 transitivity dependency를 만족한다.
다른 말로는 3NF는 만족하지 않는 것.
ex2
F = { dept_name, s_id -> i_id, i_id-> dept_name}
dept_name, s_id ->. i_id -> dept_name 이지만 i_id 가 없다고 하더라도 dept_name, s_id -> dept_name 은 trivial 관계로 설명 가능하다. 즉 transitivity dependency 는 성립하지 않고, 3NF 는 성립한다고 볼 수 있는 것.
Goals of Normalization
each relation scheme is in good form
the decomposition is a lossless-join decomposition
preferably, the decomposition should be dependency preserving.
세마포어를 사용하기에는 사용자 입장에서 코딩하기가 어렵다 보니 보다 쉬운 monitor가 도입된 계기를 만들었다.
monitior
응용프로세서가 효과적으로 호출할 수 있도록 하는 동기화 메커니즘
a high-level abstractionthat provides a convenient and effective mechanism for process synchronization
semaphore 사용 시 일어날 수 있는 상황
>> Mutual Exclusion property is violated
: mutex의 값을 증가시키는 signal 함수만 호출되어서
critical section에 여러 개의 process 가 들어와서 mutual exclusion을 위배한다.
>> Deadlock occurs
: mutex의 값을 감소시키는 wait 함수만 호출되어서
어떤 프로세스도 critical section 에 들어갈 수 없고 프로세스들 모두가 wait 함수에서
빠져나오지 못해 deadlock 이 걸리는 상황이 발생한다.
GOAL : Only one process at a time can be active within the monitor
Monitor는 class 와 매우 유사하게 구현하고 있다.
Critical Section에 1개의 process 만 들어오게 하기 위해서 즉 mutual exclusion 을 만족하기 위해서
class에
Condition Variable 추가
Wait, Signal 추가 >> condition variable에 접근할 수 있는 함수
Condition Variable하나의 프로세스만 active하고, 다른 프로세스는 기다리게 하도록 도입된게 condition 변수 입니다. condition 변수가 있어야 mutual exclusion 을 보장할 수 있습니다. condition 변수에 접근이 가능한 함수는 오직 wait 과 signal 함수만 가능합니다.
wait() 세마포어의 wait 함수는 while을 문을 만족해야 suspend 상황이 발생하지만 Monitior의 wait 함수는 호출되면 무조건적인 suspend 상황을 발생시킵니다. 즉 wait 함수를 호출한 프로세스는 컨디션 변수를 기다리는 큐에 insert 되도록 합니다.
singal() signal 함수는 wait 함수에 의해 큐에서 기다리고 있는 프로세스를 깨우는 함수입니다.
Monitor Code
1. 공유 변수 busy 는 처음에 false라서 처음 진입하는 프로세스는 조건문에 걸리지 않아 바로 critical section 에 즉 resource에 접근이 가능합니다.
2. 이후 이 프로세스는 busy 를 true로 바꿉니다.
3. 두번째로 오는 프로세스는 if 문에 걸려서 wait 함수를 호출합니다
>> mutual exclusion 속성 보장을 위해.
위에 사진처럼 monitor는 구현되어 있지만. 사용자는 옆에 사진처럼 함수만 호출하면 되는 아주 편리한 기능을 제공합니다.
즉 acquire() 를 통해 resource를 확보하고,
release()를 통해 리소스를 놓아 줍니다.
💡Liveness
Monitor를 사용 시에 synchronization을 지키기 위해 가장 중요한 함수는 wait 함수 입니다.
즉, 두 번째로 오는 프로세스는 첫 번째 프로세스가 critical section에 있으면 기다리게 됨.
wait 함수를 잘못 사용하게되면 프로세스가 아예 progress를 안하게 되는데 이것을 "DeadLock" 이라고 한다.
"deadlock"은 어떤 경우에도 빠져나갈 수 없는 경우를 말하며 이를 "indefinite block" 이라고도 한다.
💡Deadlock
two or more processes are waiting indefinitely for an event that can be caused by only one of the waiting processes
즉, 두 개 이상의 프로세스가 무한정 수행이 안되는 경우를 의미한다.
1. S와 Q를 1로 초기화 ( == binary semaphore)
2. p1이 wait(Q)를 호출 Q=0 으로 바뀜
3. Context Switch 돼서 P0 가 wait(S)를 호출해서 S가 0으로 바뀜.
4. 다시 context switch 되어 p1이 wait(s) 호출 시에 s=0이므로 밑으로 수행 안됨 즉 wait 함수 빠져나가지 못한다.
5. p0에서도 wait(q) 호출 시 빠져나가지 못함.
두 개의 프로세스 다 wait함수 빠져나가지 못해 deadlock
+ starvation : indefinite blocking. A process may never be removed from the semaphore queue in which it's suspended
deadlock과의 공통점은 무한정으로 waiting하는 것.
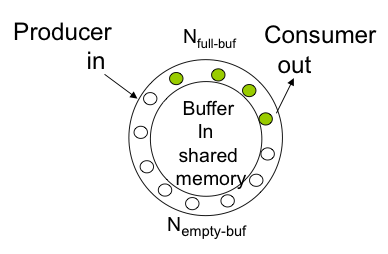
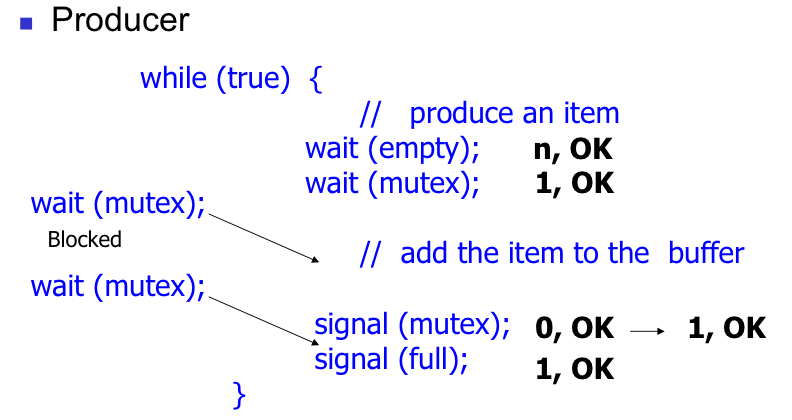
💡Bounded buffer problem
Producer / Consumer process가 따로 있고,
공유 변수는 circular queue로 구현
mutex는 producer와 consumer 모두 circular queue에 접근하기에 필요하다.
Binary mutex의 값이 1이나 0인 경우
counting mutex의 값에 제약 조건 없이 정수 값을 가짐.
ch 3장 에서는 Synchronization을 위해 Spin Lock 을 사용했었음.
Counting 의 경우에는 full 함수는 producer가 차있는 갯수를 나타내고 empty 함수는 비어있는 슬롯의 개수를 나타냅니다.
Full 0으로 초기화 / empty 는 N으로 초기화
Producer : empty가 0이라면 wait(empty) 에 진입
Consumer : full이 0이라면 wait(full) 에 진입
1. 버퍼의 크기를 체크하는 것은 wait(empty)로
2. producer가 critical section에 진입했다면 consumer는 진입하지 못하게 설정하기 위해 wait(mutex)로 관리한다.
cf. critical section은 여기서 버퍼를 채우는 영역이다.
3. critical section에서는 buffer에 item을 추가한다.
4. signal(mutex)로 mutex 값을 1로 바꾸고 consumer도 c-s에 진입 가능하게 해준다.
5.signal(full)을 호출로 buffer에 한 개 추가됐다고 설정해준다.
1. wait(full) : buffer에 차 있는 것이 없다면 waiting
2. wait(mutex) : producer가 critical section 에 진입해 있다면 mutex의 값은 0으로 consumer는 waiting
3. signal(mutex)
4. signal(empty) : buffer에 있는 아이템을 사용했기에 비어있는 공간이 늘어났다고 설정해준다.
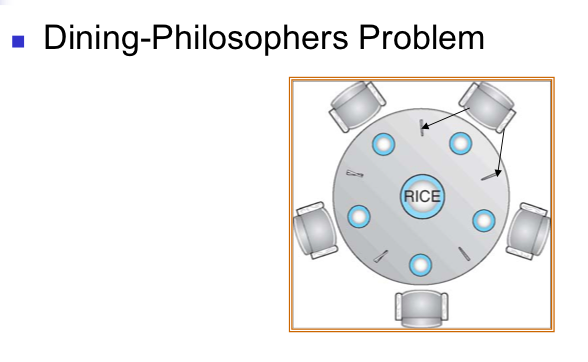
>> Dining-Philosophers Problem
: 다섯 명의 철학자가 같이 밥을 먹는데 젓가락이 철학자 사이에 하나씩 있고 서로 share한다고 가정한다. 한 사람이 젓가락을 사용하면 옆 사람을 기다려야하는 상황이다.
다섯 명의 동기화를 위해서 spinlock 사용은 복잡하여 semaphore 변수를 사용한다.
chopstick[5]는 다 1로 초기화.
chopstick[i]는 본인 기준 왼쪽 젓가락
chopstick[ (i+1) % 5 ] 는 오른쪽 젓가락
둘 중 하나라도 wait 문을 빠져나오지 못한다면 젓가락 사용 불가.
두 개를 다 확보했더라면
// eat
식사가 끝나면 왼쪽.오른쪽 젓가락에 대한 signal 함수를 호출
semaphore 값 1증가 다른 철학자 식사 가능
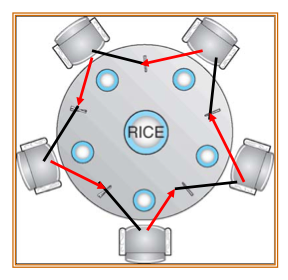
문제점 : Deadlock
다들 첫 번째 line인 왼쪽 젓가락을 가지고 있고, 오른쪽 젓가락의 available을 기다리면 아무도 식사 못하는 deadlock 상황.